
基于CMU Machine Learning Faces的人脸分类识别
基于CMU Machine Learning Faces的人脸分类识别
课程名称:统计方法与机器学习
姓名:李昕原
院校:华东师范大学 数据科学与工程学院
日期:2022.12.20
一、实验任务
获取CMU Machine Learning Faces 数据集,包含 20 人中每人 32 张含表情脸图。
任务 1:使用机器学习进行人脸分类识别,给出识别准确率
任务 2:使用聚类或分类算法发现表情相似的脸图
二、实验过程
2.1 获取并查看数据集
从http://www.cs.cmu.edu/afs/cs.cmu.edu/user/mitchell/ftp/faces.html 下载faces数据集,查看数据集文件夹的基本信息:
该数据集文件有 20 个文件夹,代表 20 个人的不同图片,每个文件夹里存有 32 张图片,而图片 的文件名代表了此人的面部表情,包括名字(an2i)、面部方向(left,right,straight,up)、表情(angry,happy,neutral,sad)、是否戴墨镜(open,sunglasses),通过划分文件名将各个元素写入对应列表,结果如图所示:

2.2 数据预处理及训练集、测试集划分
得到该人脸识别数据集的基本组成后需要将其构造为可以用于机器学习模型训练的数据。主要思路是将 name、direction、expression、sunglasses 中的各个属性定量化(如 sunglasses 中的两个属性open 和 sunglasses 的取值分别设为 0 和 1),得到 name 取值为[0,19],direction 取值为[0,3],expression 取值为[0,3],sunglasses 取值为[0,1](均取整数),由于对各个文件遍历时是顺序读取文 件,会出现某类特征全部属于训练集或测试集的情况,且训练集与测试集的样本特征重合度不高,从而导致模型训练的效果不佳,因此需要将文件的排序打乱,考虑使用 random.shuffle 实现这一要求:
1 | random.shuffle(paths) |
训练集与测试集的比例定为 3:1,将打乱顺序后的文件名拆分为词并量化为整数,并以字典的方式存储(包括四个基本属性及图像特征),构造训练集及测试集数据并查看:
1 | def data(path): |
查看训练集及训练集与测试集规模:
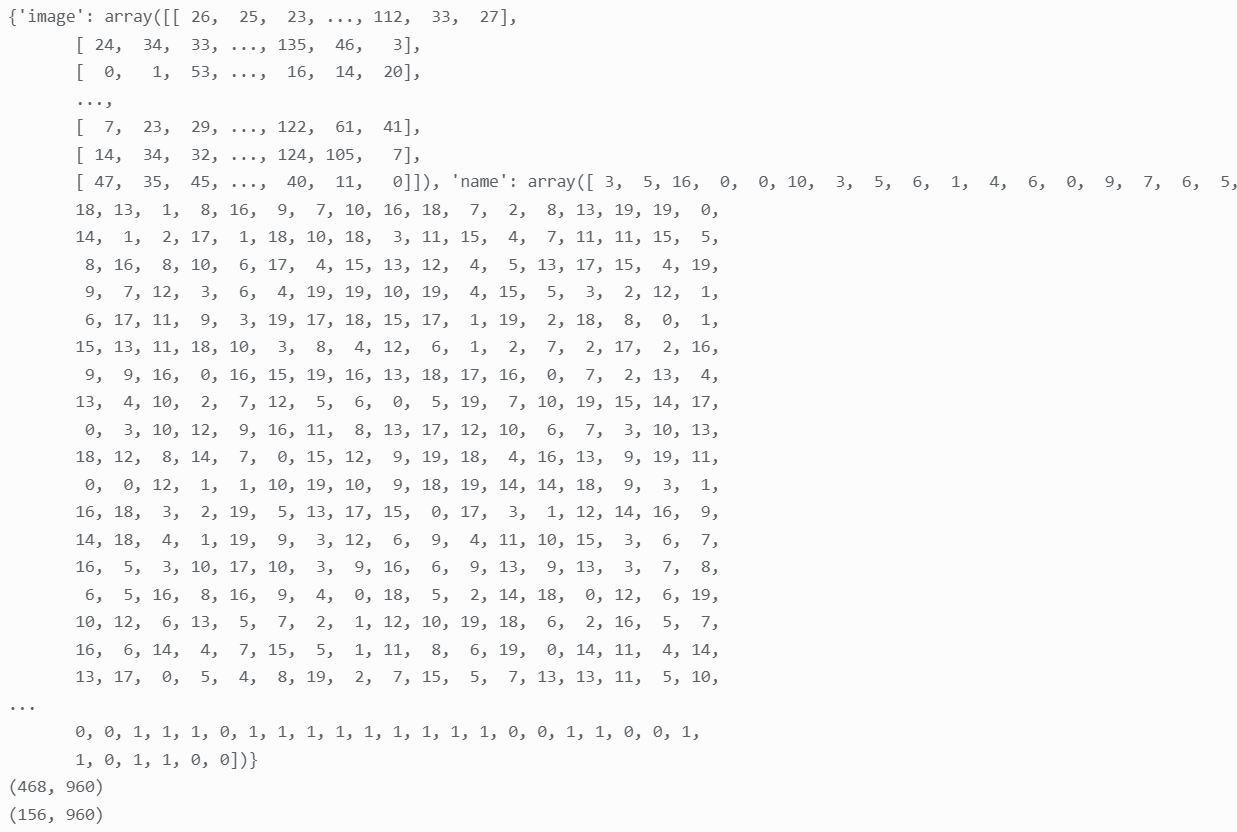
可见训练集的规模为(468,960),测试集规模为(156,960)。
2.3 使用机器学习进行人脸分类识别,给出识别准确率
在人脸分类识别任务中,name 为需要分类的标签,图像的信息为特征,将通过支持向量机 SVM与一个神经网络来实现人脸识别分类。SVM 比较重要的参数有核函数类型 kernal、惩罚系数 C 与核函数参数 gamma,将使用网格搜索寻找最优超参数:
1 | #SVM |
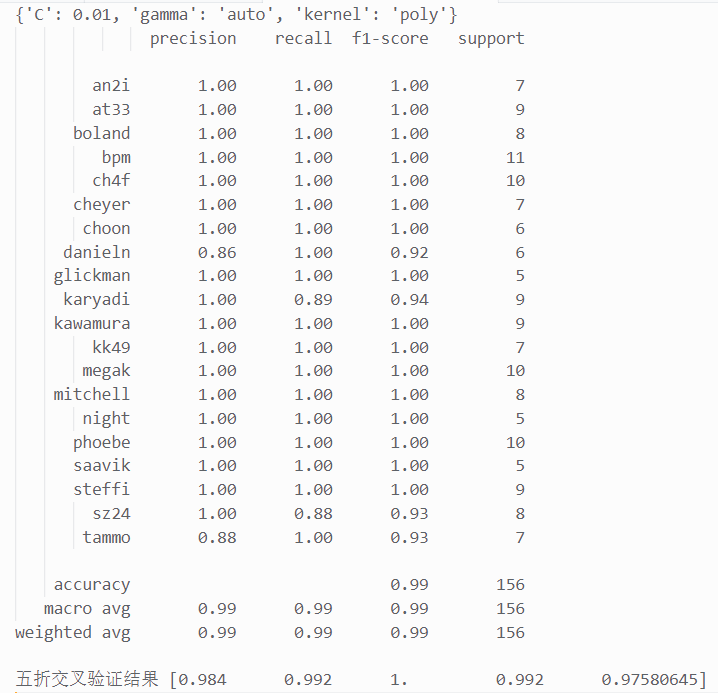
可见最优的超参数组合为多项式核函数 poly、惩罚系数 C=0.01,核函数参数 gamma 为auto(1/n_features),最终的 SVM 模型人脸分类识别准确率达到了 0.99,且五折交叉验证的结果也很 好,可见分类效果非常理想。 接下来实现一个神经网络来进行人脸分类识别。神经网络的实现依靠深度学习库 Keras 实现,将通过 keras.model.Sequential 构建网络模型,model.compile 与 model.fit 来分别配置训练方法并进行训练。神经网络配置的选择方面,采用一层全连接层,为了保证充分拟合的同时避免过拟合,神经元数 目设为 30;激活函数方面,选择 softmax 激活函数,可以增加区分对比度并提高学习效率,同时softmax 连续可导无拐点,对于梯度下降法非常必要;正则化方面选择 L2 正则化来提高泛化能力;学 习率设置为 0.01,采用随机梯度下降法 SGD,损失函数则使用交叉熵损失函数,在模型效果差的时候学习速度比较快,在模型效果好的时候学习速度变慢。

最后要将神经网络输出的one-hot 编码转为对应类别以通过 sklearn 中的 classification_report 计算准确率,并将训练过程可视化作图:
1 | #neural networks |
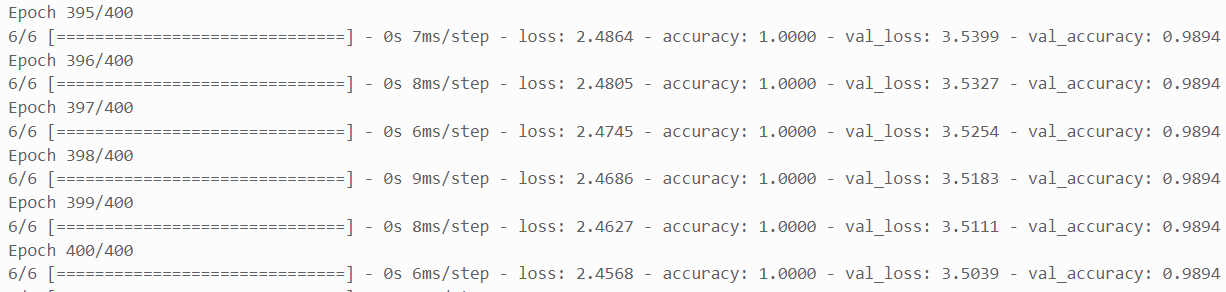
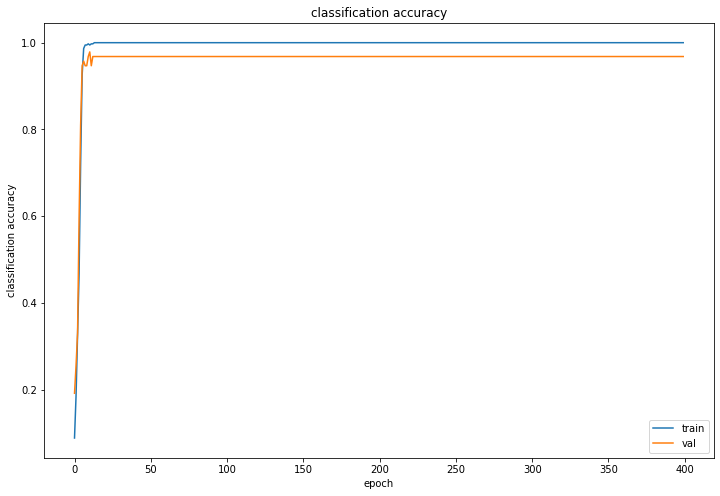
损失下降与训练集、测试集准确率图:

最终报告:
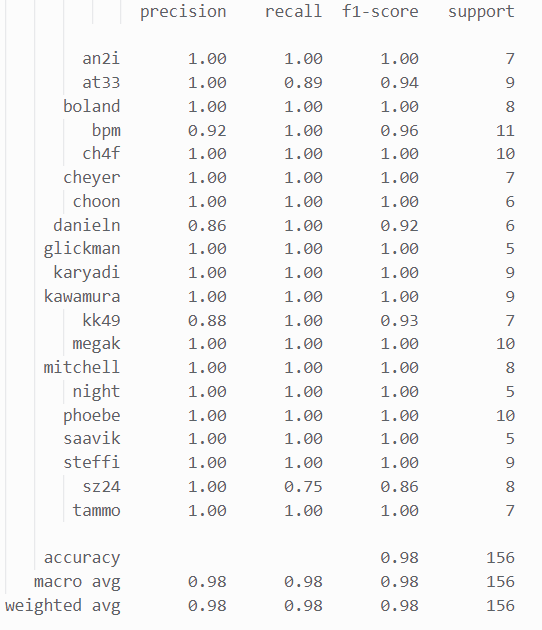
可见神经网络人脸分类识别的最终识别准确率达到了0.98,效果也非常理想。
综上,人脸分类识别任务通过 SVM 支持向量机、神经网络分别实现,准确率均在0.99 左右,效果很好。
2.4 使用聚类或分类算法发现表情相似的脸图
在该数据集中人物的表情特征包括人脸朝向 direction、人的表情 expression、是否戴墨镜sunglasses,而发现表情相似脸图这一问题的标签为表情 expression,首先通过任务一中使用的 SVM 与神经网络进行人脸表情识别,代码与之前任务的人脸识别分类类似(仅将标签由 name 修改为expression),故不再列出,仅列出结果。
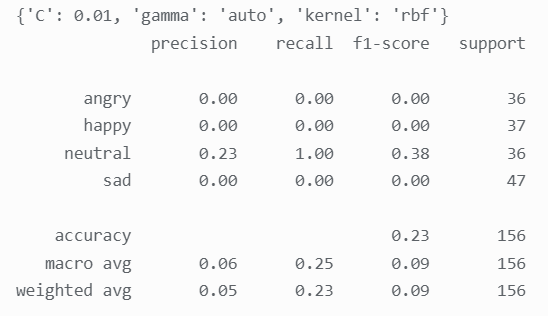
** **SVM:
神经网络及可视化结果:
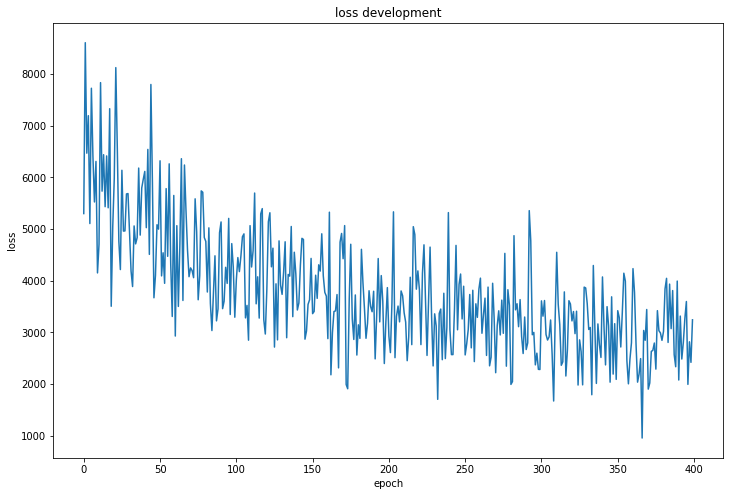
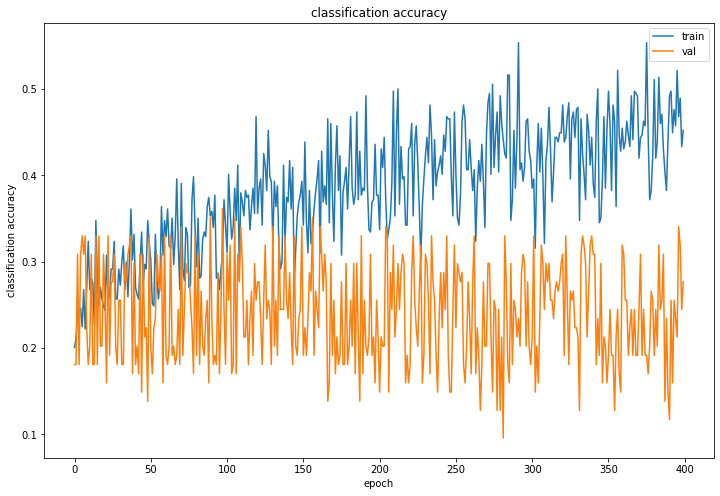
由图可知神经网络训练过程中损失波动很大且下降幅度小,而训练集与测试集的准确率都有较大 波动,可知分类效果较差,报告也验证了这一点:
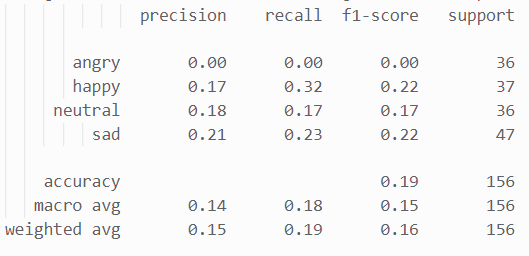
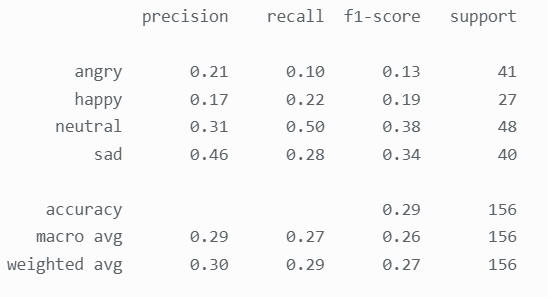
SVM 的相似表情识别准确率为 0.23,神经网络为 0.19,这与人脸分类识别时两个模型的高分类准 确率大相径庭,效果非常不理想。接下来使用聚类算法KMeans 尝试进行表情相似分类,由于表情expression 有四类,故无监督学习 KMeans 的 n_clusters 设为 4:
1 | clf = cluster.KMeans( |
聚类后将每一类的前 10 个样本对应的图像输出:




直观上看感觉表情相似聚类效果一般,报告也证明了确实效果不佳:
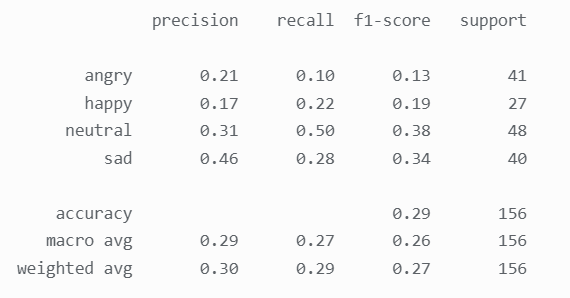
KMeans 聚类的准确率仅有 0.29,比 SVM 与神经网络的准确率稍高一点,可见不论是分类算法 还是聚类算法在表情相似识别这一问题上均效果不佳,通过 PCA 对数据进行降维再进行 KMeans 聚 类:
1 | #PCA降维 |
对表情分类识别的聚类簇进行可视化并标记聚类中心:
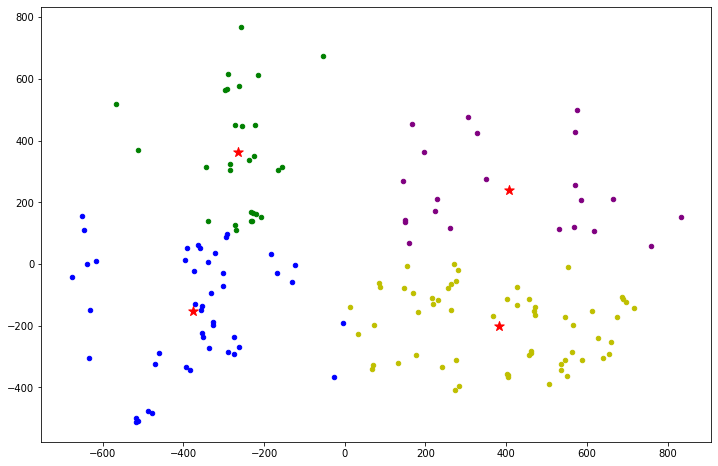
准确率依然较低,推测三种分类与聚类算法准确率均较低的原因有以下两点:
- 数据集除人脸外还包括了与人脸无关的背景,因此存在比较严重的噪声;
- 数据集规模较小且是两通道灰度图,人脸表情的特征损失较多。
2.5 使用 SVM 识别人脸方向与是否戴墨镜
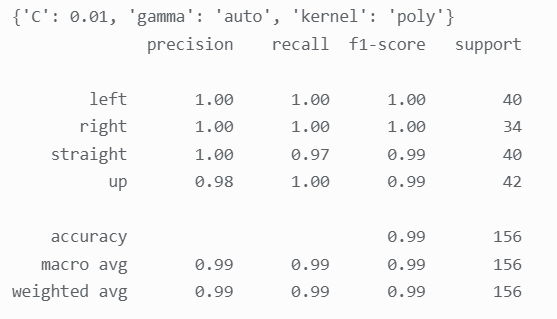
前面两个任务分别将 name 与 expression 作为标签,而剩下的人脸方向 direction 与是否戴墨镜sunglasses 并未做过分类识别任务,因此基于 SVM 将这两个特征作为标签进行分类识别,代码与上 述相似故不展示,仅展示分类效果及分类结果部分样本的图像: 人脸方向:

是否戴墨镜:
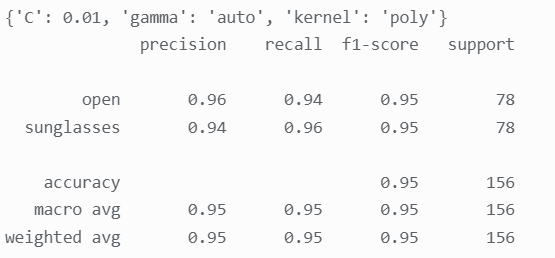

样本分别为人脸朝向右侧与不戴墨镜的情况,准确率分别为 0.99 与 0.95 效果均不错,可见除了 表情 expression 其余标签的分类识别效果均很优秀,这同样印证了上述人脸表情特征损失较多这一推论。
三、总结
本次实验获取并查看了 CMU Machine Learning Faces 数据集,通过 SVM 与神经网络模型训练完 成了任务 1:人脸分类识别,准确率均在 0.99 左右,取得了不错的效果,后通过 SVM、神经网络与KMeans 聚类进行任务 2:表情相似识别,但效果不佳,并分析了准确率较低的两点原因(背景噪声 严重、人脸表情特征损失较多)。此外还对另外两个标签人脸朝向与是否戴墨镜进行分类识别,准确率也均在 0.95 也上,同样取得了不错的效果。
 wechat
wechat